Introduction
Last Friday we released version 0.11.0 of our Open Source API Management System wicked.haufe.io (GitHub Repository, Release Notes). Over the course of the last couple of weeks our focus has been to make deployments to production easier and how to enable deployments to alternative runtimes (other than using docker-compose), or at least how to make them easier.
This blog post will explain some of the changes and enhancements that were made and how you can update your existing API Configurations to benefit from them.
Recap - Deployment Architecture
To set the scene a little, let’s recap how the deployment architecture of a typical wicked deployment looks like:
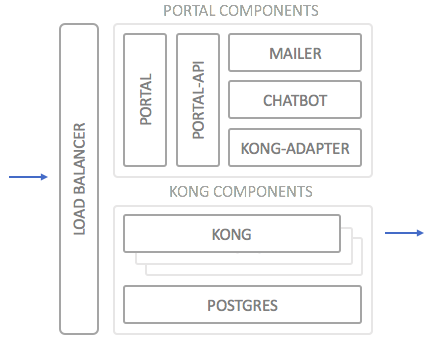
The two main blocks are the portal components and the Kong components (the actual API Gateway). Both blocks are made up of further smaller containers which fulfill specific tasks, such as the “mailer” or the “portal”. The Kong components consist of n Kong Gateways (depending on your scalability needs) and a Postgres database in which Kong stores its configuration.
In front of both blocks resides the load balancer. This can be any load balancer capable of doing SSL termination and resolving VHOSTs (i.e. almost any LB). The default implementation is leveraging docker-haproxy for this purpose, but using an Apache LB, nginx proxy, or even an ELB or Azure LB is equally possible (albeit not preconfigured).
Configuration and Persistent Data
The API Portal needs to keep its configuration somewhere, and also needs to keep some data persistent. The configuration data is static and is usually retrieved from a source code repository (preferably git). This means this data does not need to be persisted, as it can be recreated from scratch/from code any time (“STATIC CONFIG”). Data which comes from the usage of the API Portal (users, applications, subscriptions and such) does need to be persisted in some way (“PERSISTENT DATA”):
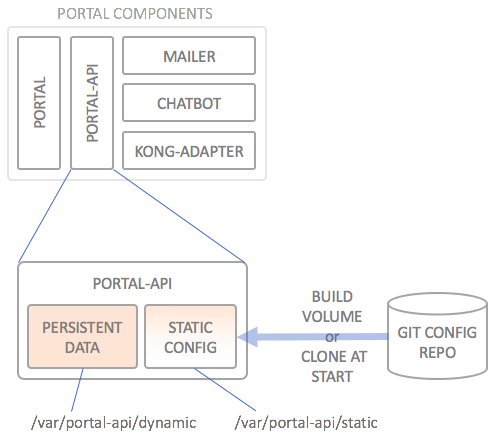
How persistent storage is kept varies from orchestration to orchestration, but this is usually not a big issue; it’s different, but as long as the runtime is able to mount a persistent volume at /var/portal-api/dynamic which remains the same over the entire lifecycle of the portal-api service container, all is fine.
With regards to the static configuration which usually resides in the /var/portal-api/static folder, the default deployment using docker-compose has always assumed that your are able to build a private image using docker build on the docker host/swarm you are deploying to. This is quite an issue with e.g. Kubernetes or Mesosphere which always assume that images are downloaded (“pulled”) to the system, and not built on the cluster.
The first workaround you can apply to circumvent this is to build a private image derived from haufelexware/wicked.portal-api which prepopulates the /var/portal-api/static directory with your API Configuration and push that to a private repository, from where the orchestration runtime (e.g. Kubernetes or Mesos) pulls it when deploying. This has a couple of obvious drawbacks, such as needing a private docker repository, or that you need to build a new docker image each time you want to deploy a new API configuration.
Static Configuration using git clone
In order to make the use case of updating the API configuration easier, we enhanced the startup script of the portal-api container to be able to by itself clone a git repository into the /var/portal-api/static folder. By specifying the following environment variables for the portal API container, this will be done at each container creation and restart:
| Variable | Description |
|---|---|
GIT_REPO |
The git repository of the API configuration, e.g. bitbucket.org/yourorg/apim.config.git |
GIT_CREDENTIALS |
The git credentials, e.g. username:password |
GIT_BRANCH |
The branch to clone; if specified, HEAD of that branch is retrieved, otherwise master |
GIT_REVISION |
The exact SHA1 of the commit to retrieve; mutually exclusive with GIT_BRANCH |
This enables running the “vanilla” portal API image also in environments which do not support building docker images on the docker host, such as Kubernetes.
Automatic Configuration Refresh
The portal API container now also calculates a “config hash” MD5 value of the content of the configuration directory at /var/portal-api/static as soon as the container starts. This is not depending on the git clone method, but is also done if the configuration is prepopulated using a derived docker image or if it still uses the data only container approach to mount the static configuration directory into the container.
This configuration hash is used by the other containers to detect whether a configuration change has taken place. Except for the portal API container, all other wicked containers are stateless and draw their configuration from the API configuration (if necessary). This means they need to re-pull the settings as soon as the configuration has changed. When using the docker-compose method of deploying, this wasn’t a big issue if you just did a docker-compose up -d --force-recreate after creating the new configuration container, but with runtimes such as Kubernets, this would introduce quite some overhead each time the configuration changed: All dependant containers would need to be restarted one by one.
This is how the core wicked containers behave now:
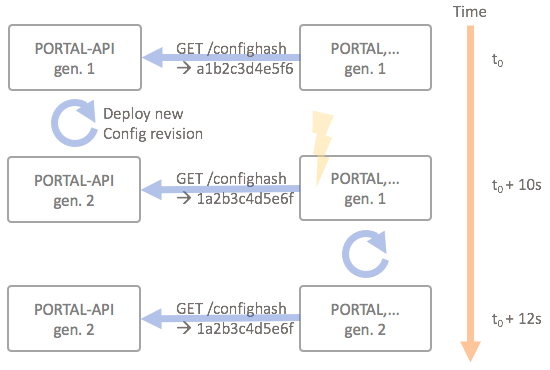
The diagram above depicts how the portal API interacts with e.g. the portal container (Kong adapter, mailer and chatbot also behave exactly the same):
- At initial startup, the portal container retrieves the current config hash via the
/confighashend point of the portal API; this hash is kept for comparison in the container - The configuration is updated, which triggers a CI/CD pipeline
- The CI/CD pipeline extracts the current git revision SHA1 hash and updates the
GIT_REVISIONenvironment variable for theportal-apicontainer (this is highly depending on the orchestration runtime how this works) - The CI/CD pipeline triggers a recreate on the
portal-apiwhich in turn clones the new revision of the API configuration repository at startup (via theGIT_REVISIONenv variable) - At the next check interval (every 10 seconds) the portal detects that a configuration has taken place, as the config hash returned by
/confighashhas changed - The portal triggers a restart of the portal; when starting anew, the portal will retrieve the new config hash and restart polling the
/confighashend point
This means that all wicked containers can be treated as individually deployable units, which makes your life a lot easier e.g. when working with Kubernetes.
The polling functionality is built in to the wicked Node SDK, which means that any plugin or authorization server built on top of this SDK also automatically benefits from the automatic config hash checking; example implementations of authorization servers are wicked.auth-passport (for social logins like Twitter, Facebook, Google+ and GitHub) and wicked.auth-saml (for SAML identity providers).
Upgrading to wicked 0.11.0
In case you are running wicked in a version prior to 0.11.0, you do not necessarily have to update any of your deployment pipelines or docker-compose.yml files. The git clone method does though make updating the API configuration a lot simpler, so we recommend you to change your docker-compose.yml in the following way:
- Remove the
portal-api-data-staticservice entirely; it is no longer needed - Add
GIT_REPO,GIT_CREDENTIALS,GIT_REVISIONand/orGIT_BRANCHto thevariables.envfile - Remove the entry
portal-api-data-staticfrom thevolumes_fromsection of theportal-apiservice - Additionally provide values for the
GIT_*env vars at deployment time, in your CI/CD scripting solution
You can find more and more detailed information in the documentation.
Oh, and one more thing
We also implemented the promised support for the OAuth 2.0 Authorization Code Grant since the last blog post (actually in 0.10.1). Just for the sake of completeness.
If you have any questions or suggestions regarding wicked, please file an issue on GitHub. Hearing what you think and what kinds of scenarios you are trying to implement using wicked is super exciting!