The Strata Data conference is an major event related to latest trends in data area. I have attended this year Strata in London and would like to share my impressions.
Like most conferences Strata Data is a hit and miss - you either spend an hour with your yaw dropped in state of enlightenment or you fall to sleep during long marketing pitch. I was lucky this time and scored couple of great sessions.
As I am mainly interested in big data architecture and data engineering, most sessions I attended were related to this area, so my impressions will focus on these topics as well.

TL;DR
Streaming is most fancy thing in data engineering , batch is an embarrassing past and no one wants to talk about it.
The same applies to classical Hadoop/MapReduce as a processing engine - Spark ate it already.
New post-Hadoop tools like Apache Kudu, Beam or Flink are emerging.
Machine Learning, Deep Learning, AI and supporting technologies are most trending topics.
Data lakes are considered an obvious part of an infrastructure.
Kafka is a everywhere, Flume is nearly dead.
Data Architecture
The best two sessions, during this year Strata, for anyone interested in data architecture.
Both sessions were hosted by authors of my favourite Hadoop book: “Hadoop Application Architectures: Designing Real-World Big Data Applications”. I recommend this book wholeheartedly to anyone interested in Hadoop/big data architecture patterns.
Just two notes:
- Studying “Hadoop: The Definite Guide” before helps,
- The book, published in 2015, is already partially outdated and new revision, as authors told me, is already in writing(what only shows how quickly data landscape is changing).
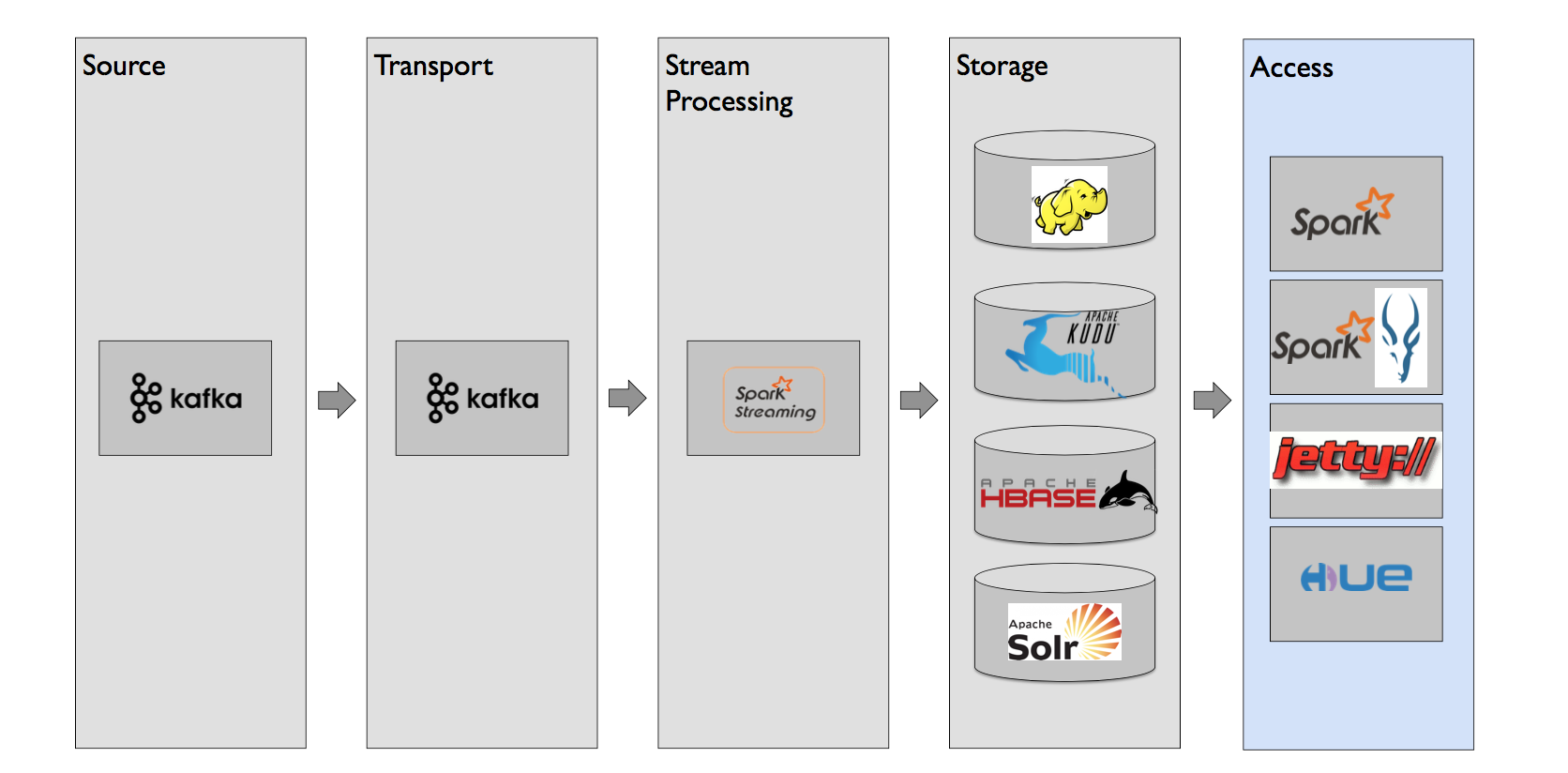
That was most detailed, technical oriented presentation I have seen on this year Strata. In general, presenters demonstrated a reference data architecture consisting of Kafka as both - an universal data source and a data transport mechanism, Spark/Spark Streaming as processing engine, HDFS, Apache Kudu, Apache HBASE and Apache Solr as a storage, SparkSQL, HUE, Impala and REST servers (jetty) as a data access layer. Many other alternative technologies like Flink, Flume, Beam, Storm, Hive, elasticsearch, Kibana/Banana etc were discussed as well.
It is over 200 slides presentation, going sometimes very deep into details but really worth studying.
What is interesting, this architecture pattern was visible in many other independent presentations I have seen on Strata.
Other interesting sessions in this area were:
-
Architecting a data platform John Akred (Silicon Valley Data Science), Stephen O’Sullivan (Silicon Valley Data Science) - a bit too high level but good as an introduction. Presentation available on request.
-
Creating real-time, data-centric applications with Impala and Kudu Marcel Kornacker (Cloudera) - introduction to Apache Kudu.
-
Organizing the data lake Mark Madsen (Third Nature) - this presentation was very interesting one. Despite of the title it is not really focused on data lake but touches a lot of other areas of data and architecture as well. Not very technical but very rich on conceptual level.
-
Presto: Distributed SQL done faster Wojciech Biela (Teradata), Łukasz Osipiuk (Teradata) - introduction to Presto.
Data Lake
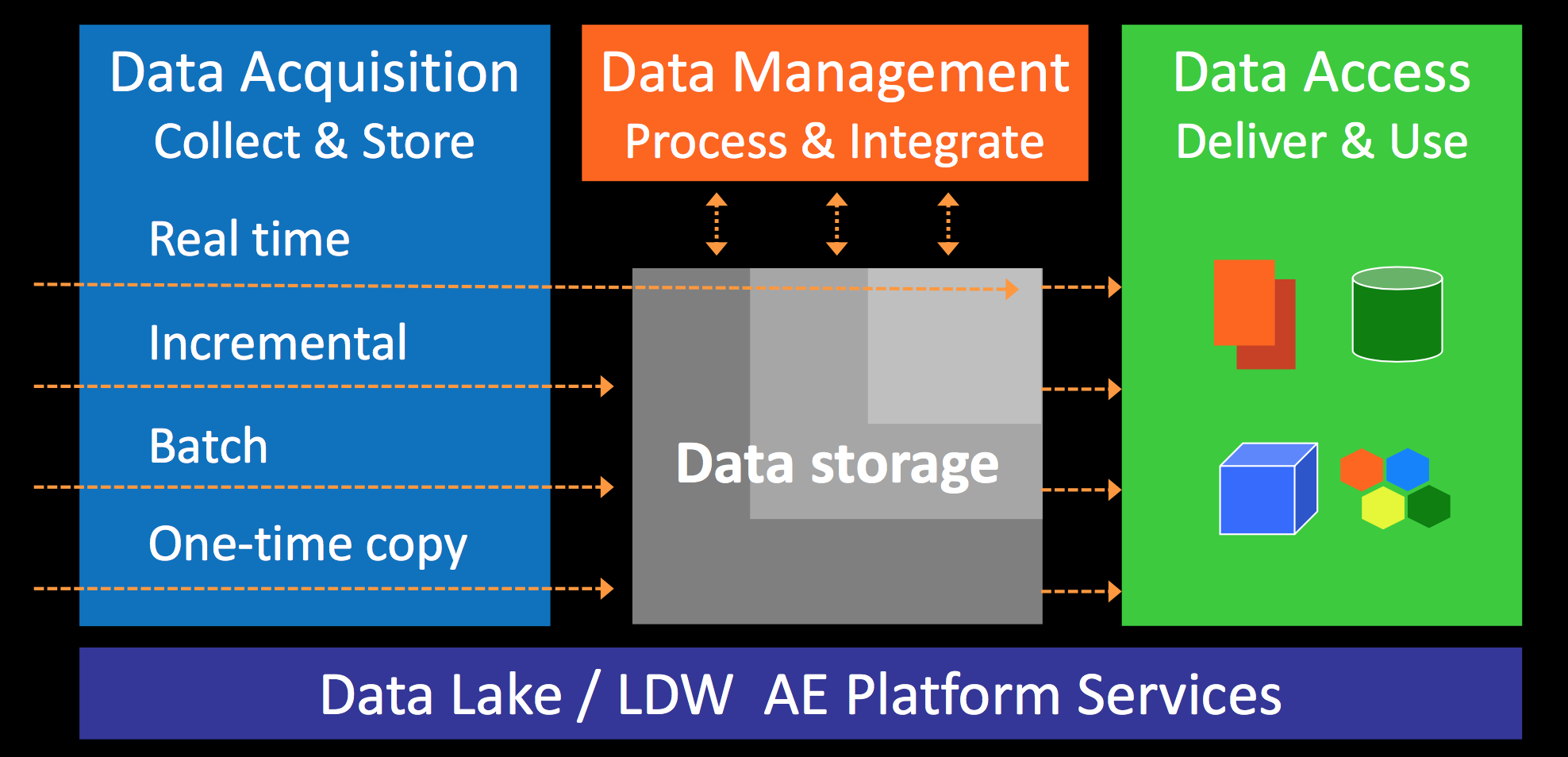
Data lake was mentioned in many presentations as an obvious part of data infrastructure, but only 2 presentations were dedicated directly to this topic:
-
Organizing the data lake Mark Madsen (Third Nature) - this presentation was very interesting one. It shows the concept from unusual perspective and touches a lot of other areas of data and architecture as well. Not very technical but very rich on conceptual level.
-
Building a modern data architecture for scale Ben Sharma (Zaloni) - despite of name - mostly dedicated to data lake concept but rather on the high level.
My impression was that data lake is a “business as usual” topic - similar to having HDFS as a storage - and being obvious and not anything new anymore. It is not anymore considered as a “all-in-one” solution but rather as a foundation broader data architecture.
Interesting real-life implementation cases:
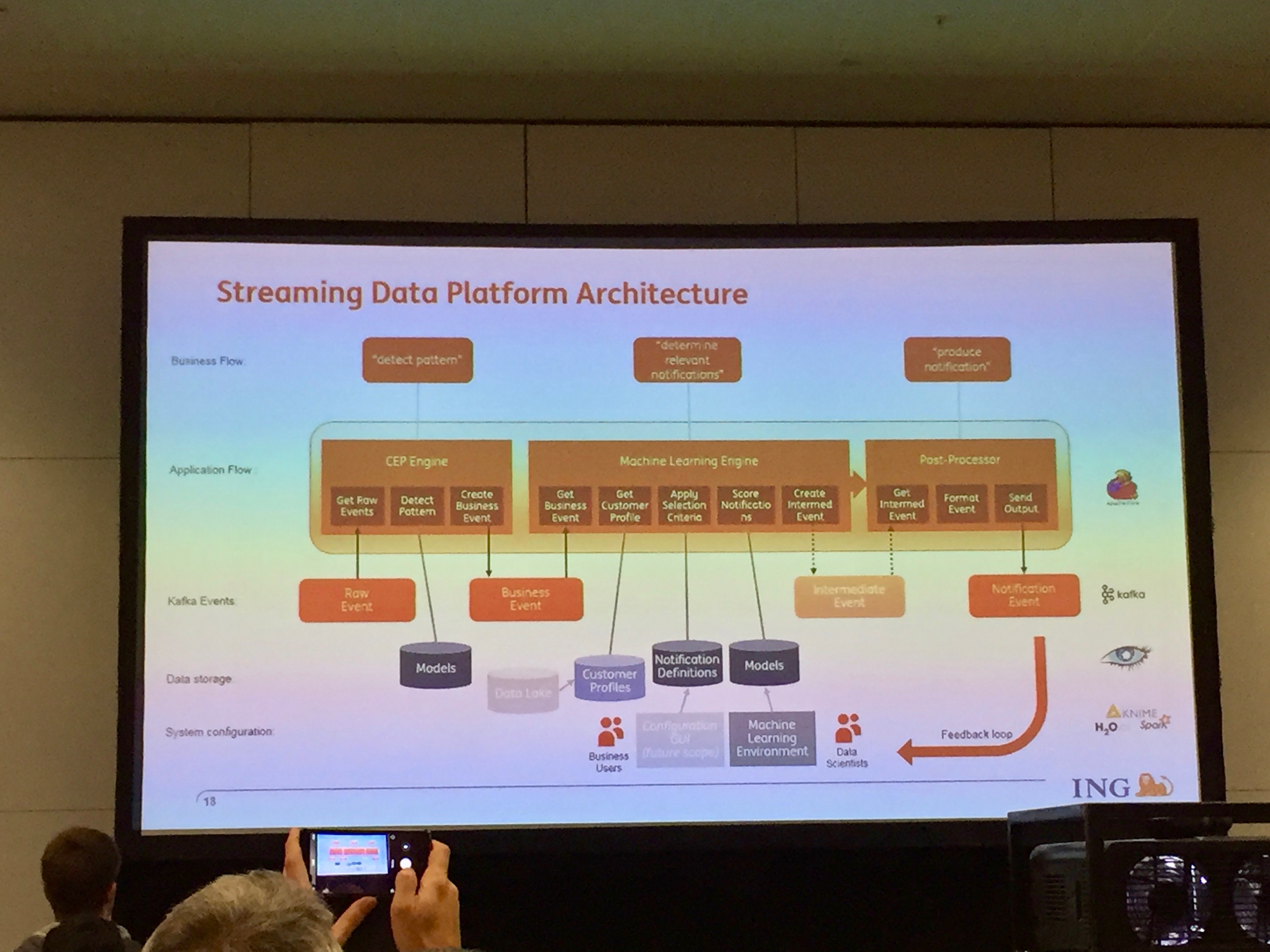
- Fast data at ING: Utilizing Kafka, Spark, Flink, and Cassandra for data science and streaming analytics Bas Geerdink (ING) - an interesting example of real life implementation of fast data concept using latest big data tools and covering areas of recommendation, machine learning, actionable analytics etc. Unfortunately presenter did not share his presentation - I have only couple of pictures.
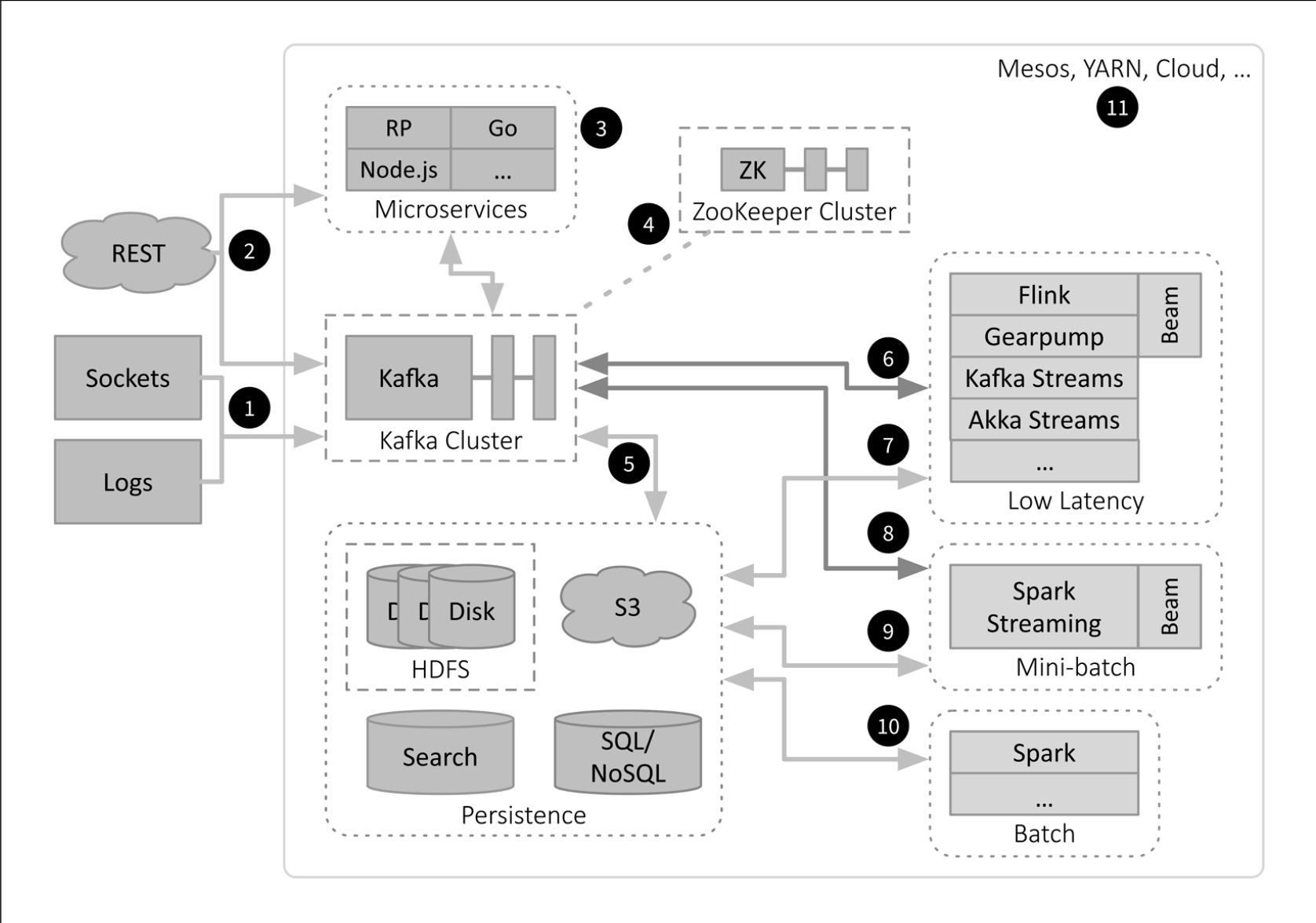
- Hadoop as a service: How to build and operate an enterprise data lake supporting operational and streaming analytics Phillip Radley - an exxample of succesful data lake implementation.
Machine Learning
Trends:
- Streaming is recommended way of moving data and Kafka is a default tool for this task.
- Message queues are considered a core integration tools.
- Spark is default processing engine for both batch and streaming - what helps is that nearly the same Spark code can be used for both tasks what simplifies implementation.
- The Apache Flink is a new, real-time, low latency alternative to Spark.
- Storage offers many options depending on purpose: object storage as S3, HDFS for files, various flavours of NoSQL (HBASE, MongoDB, Cassandra etc) and a new, still in incubation status, option: Apache Kadu.
- Real-time, near real time, batch requires different tools accordingly: Flink (low latency), Spark Streaming (micro batches), Spark (batch)
- There are some initial attempts to marry microservices with data architecture.
- Most presented use cases revolves around Machine Learning, Deep Learning, Data Visualisation, Actionable Analytics.
- Most non architecture/data engineering sessions very dedicated to different flavours of machine learning.
- Many presenters stated that big data technology maturity is still on low level across the market, with knowledge gap, lack of experienced resources and ever changing technology and its complexity being major obstacles.
- New concept of fast data - use case define how fast you want to go with data and what toolset and architecture you need - good read here
New technologies worth to follow:
Resources
I have copies of all presentations shared during Strata Data London 2017. I will drop them in some shared place and will update this post later.
Final word
This post shares only couple of my impressions from Strata Data 2017 in London. If anyone would like to discuss it in details, please do not hesitate to contact me.