In Haufe we are using AWS Organizations service with hundreds of accounts and multiple OUs, therefore it was a challenge for us to offer a centralised backup solution for files.
AWS does not offer an out-of-box backup service for your files, so we needed to be creative.
Considering this requirement, we realised that S3 bucket replication can be a good candidate in order to achive our goal. Of course, having a one-to-one replicated bucket solution does not scale, therefore we were thinking to create ONLY one in the centralised replicated S3 bucket, which stores all the files from multiple S3 buckets sources.
Amazon S3 replication enables automatic, asynchronous copying of objects across Amazon S3 buckets. Buckets that are configured for object replication can be owned by the same AWS account or by different accounts.
There was one last challenge: how do we organise the centralised S3 bucket, in order to have a well structured folder/prefix for each source S3 bucket. The solution came from the centralised S3 bucket permission policy, where we used the ${aws:PrincipalAccount} context key.
Prerequisites
In order to keep data encrypted at rest, you have to create at least 2 KMS keys, used by s3 to encrypt data :
- one in centralised account
- one in each source account
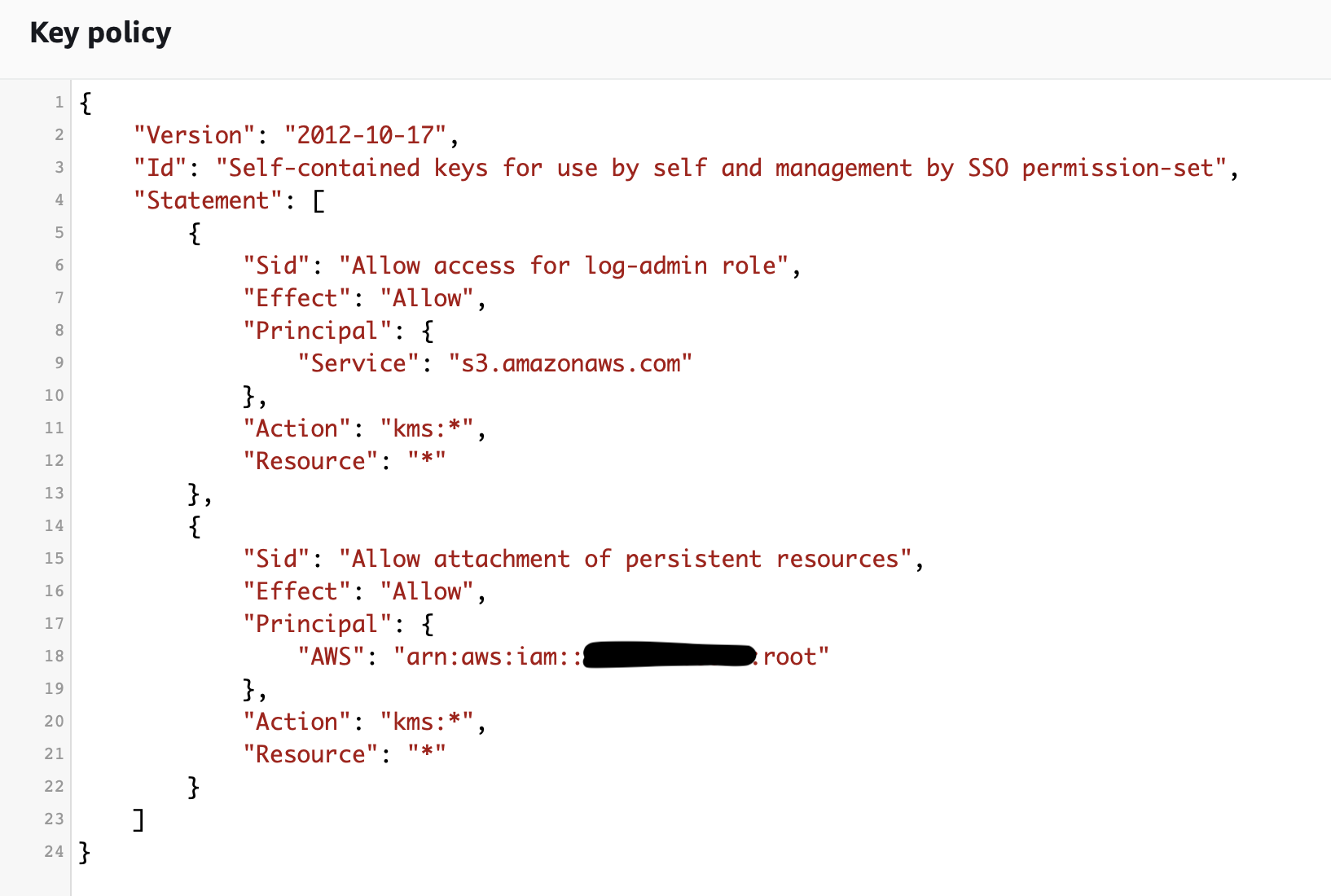
From AWS console -> KMS -> Customer-managed keys -> Create key. One important aspect is to create a valid kms policy, which allows AWS services to encrypt/decrypt data. Below you can see the kms policy for each type of key:
- KMS for centralised bucket, contains a condition based on OrganizationID, which allows all AWS accounts in our AWS Organization to use it

- KMS for each source AWS account
Create S3 Buckets
We have to create 2 buckets one in each source account and another one in the centralised one. From AWS console, go to S3 service and select Create bucket

- Write the name of the source/centralised bucket
- Enable Bucket version
- Enable server side encryption and specify kms key created in the previous step
The next step is valid ONLY for centralised S3 bucket, in order to have a valid policy based on aws:PrincipalAccount and including Organization ID condition:

Replication is configured via rules.
You have to create a rule in each source S3 bucket to replicate objects to the centralised S3 bucket. The bellow step is done only in sources AWS accounts:
- Go to the Amazon S3 console
- Click on the name of the source S3 bucket
- Click on the Management tab
- Click Create replication rule
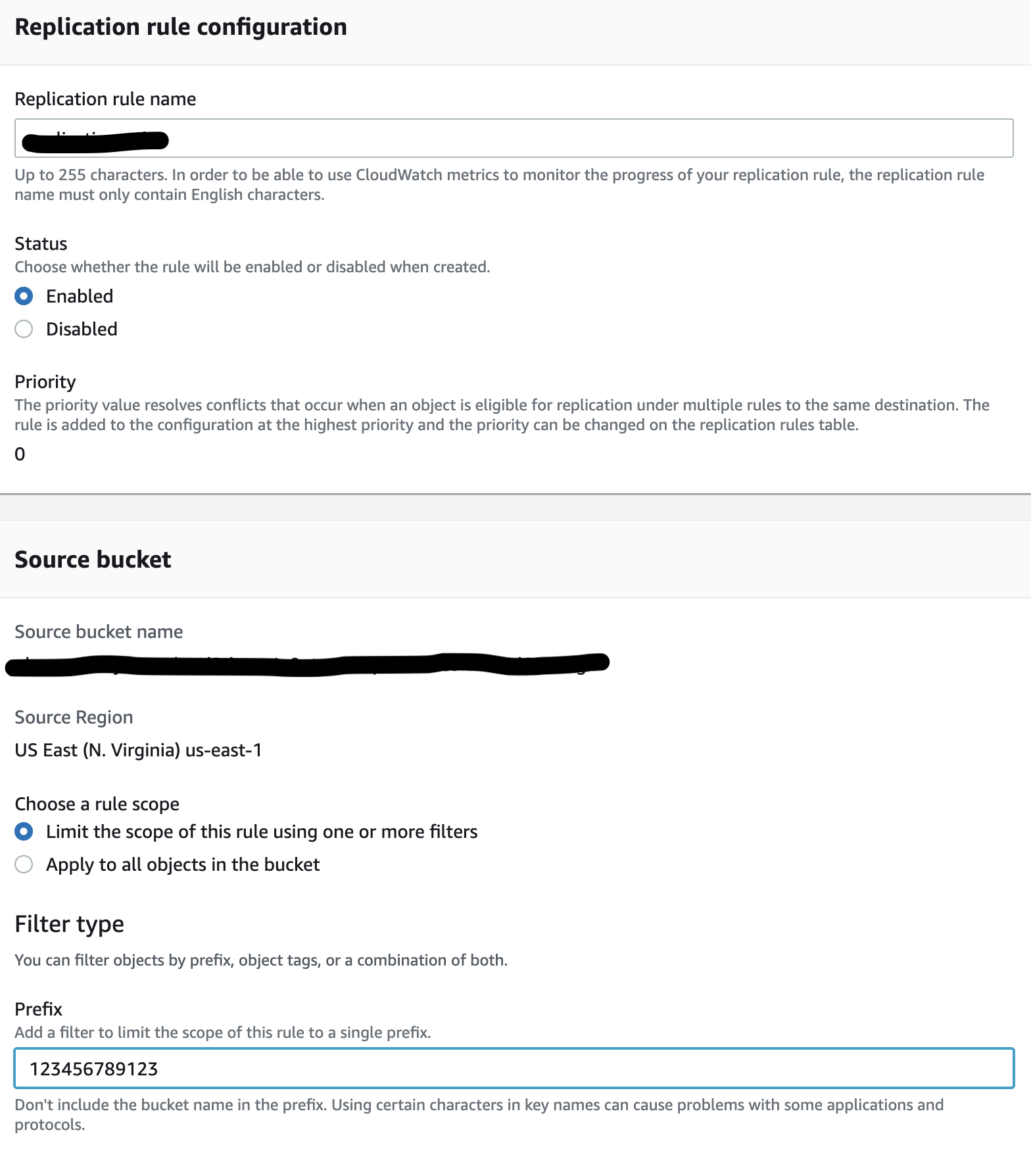
- Specify Replication rule name
- Leave Status set to enabled
- Choose a rule scope select, Limit the scope of this rule using one or more filters
- Specify for prefix/folder the account id value, in order to be sync with centralised S3 bucked policy based on ${aws:PrincipalAccount}
- eg. 123456789123 <- account id
- Specify for prefix/folder the account id value, in order to be sync with centralised S3 bucked policy based on ${aws:PrincipalAccount}
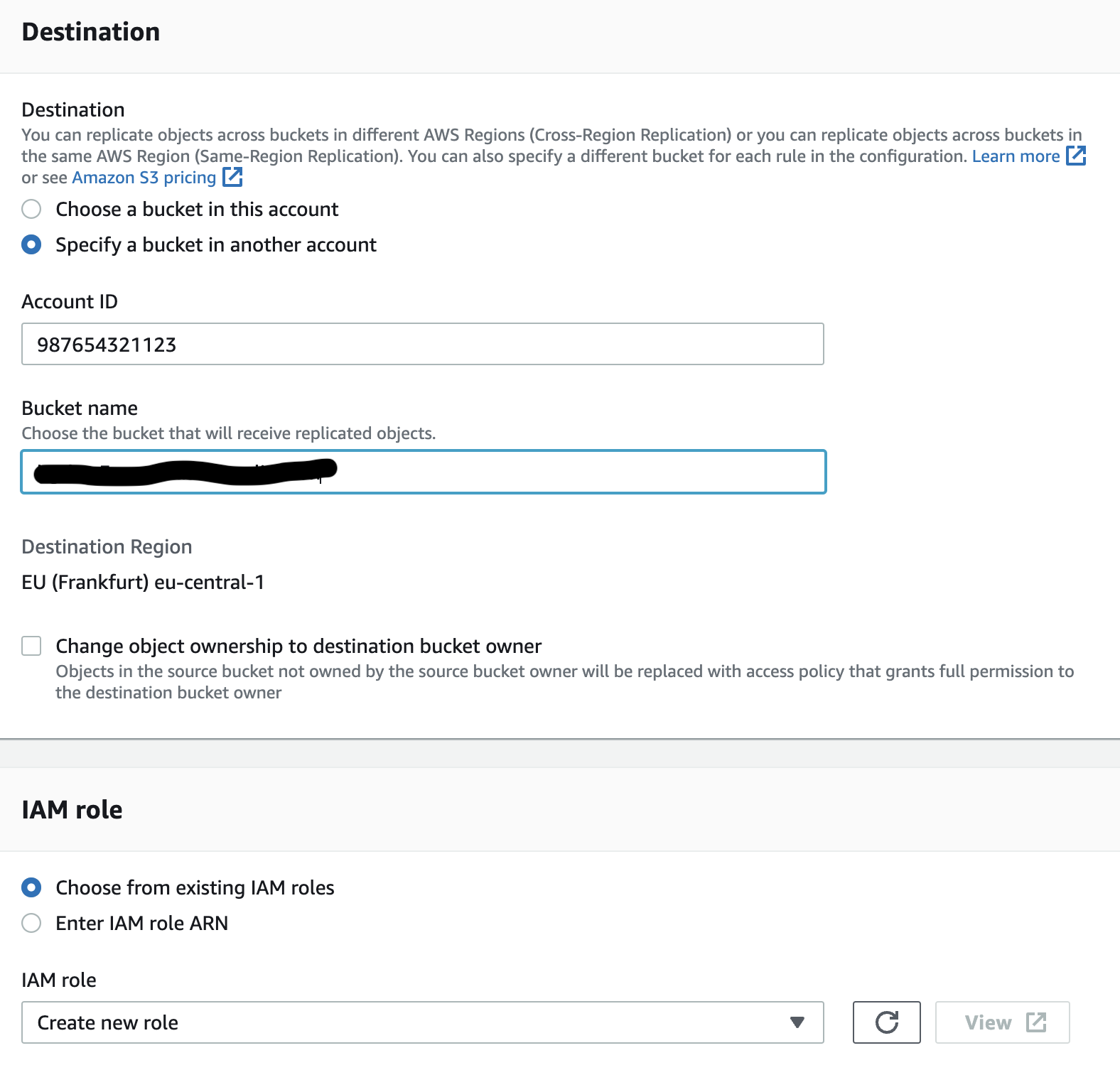
- For Destination select Specify a bucket in another account
- Specify the account id of the centralised S3 bucket
- Specify the centralised S3 bucket name created in the prerequisites chapter
- Check box Change object ownership to destination bucket owner
- For IAM Role leave Choose from existing IAM roles selected, and select Create a new role from the search results box
- A new IAM role will be created, which has privileges to both S3 buckets and to KMS keys in both accounts
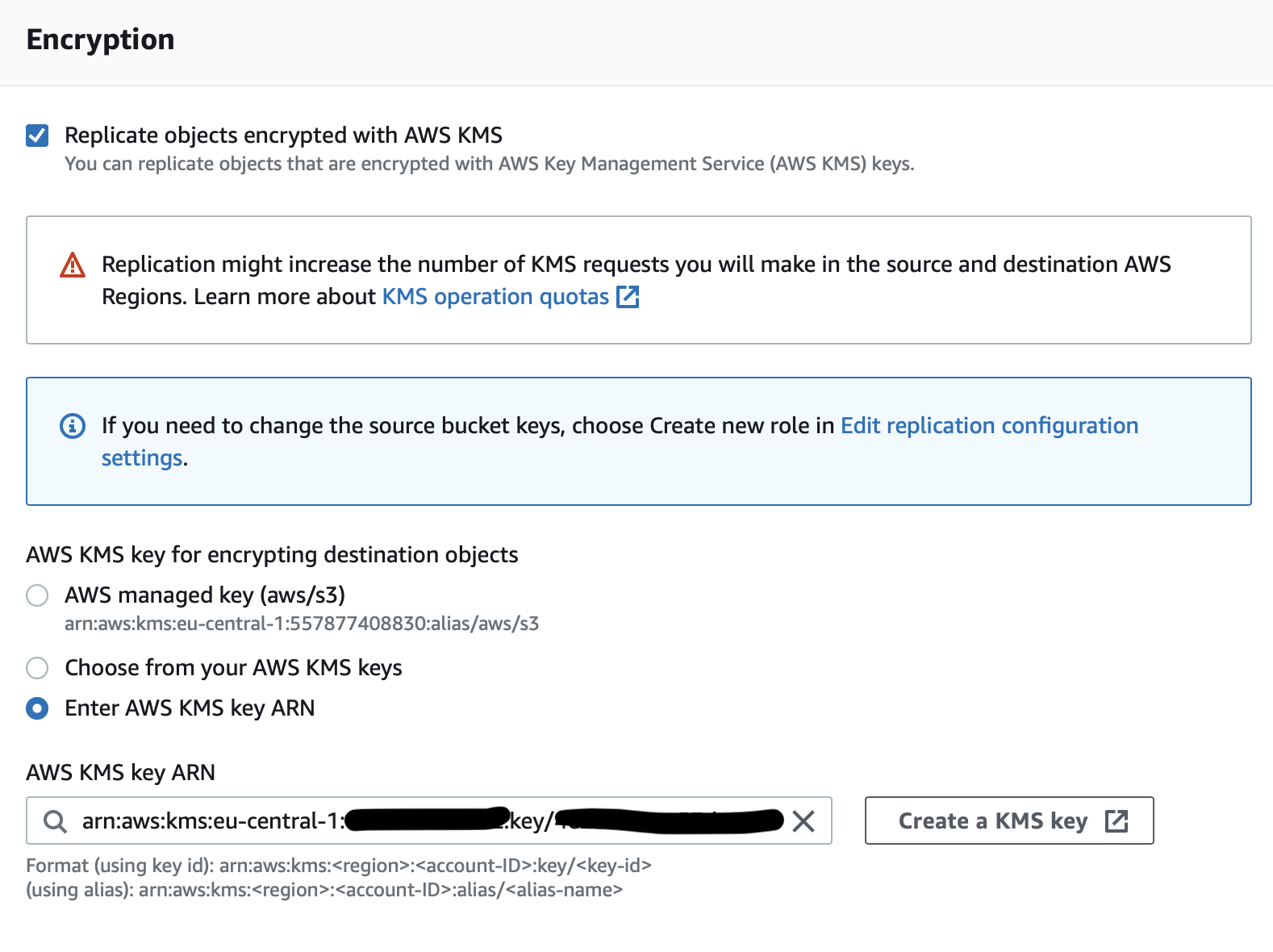
- For Encryption, choose Replicate objects encrypted with KMS keys and select Enter AWS KMS Key ARN
- For source objects check box the KMS key name created in the prerequisite step in source account
- For destination objects get the KMS key ARN from the centralised account and paste in the field
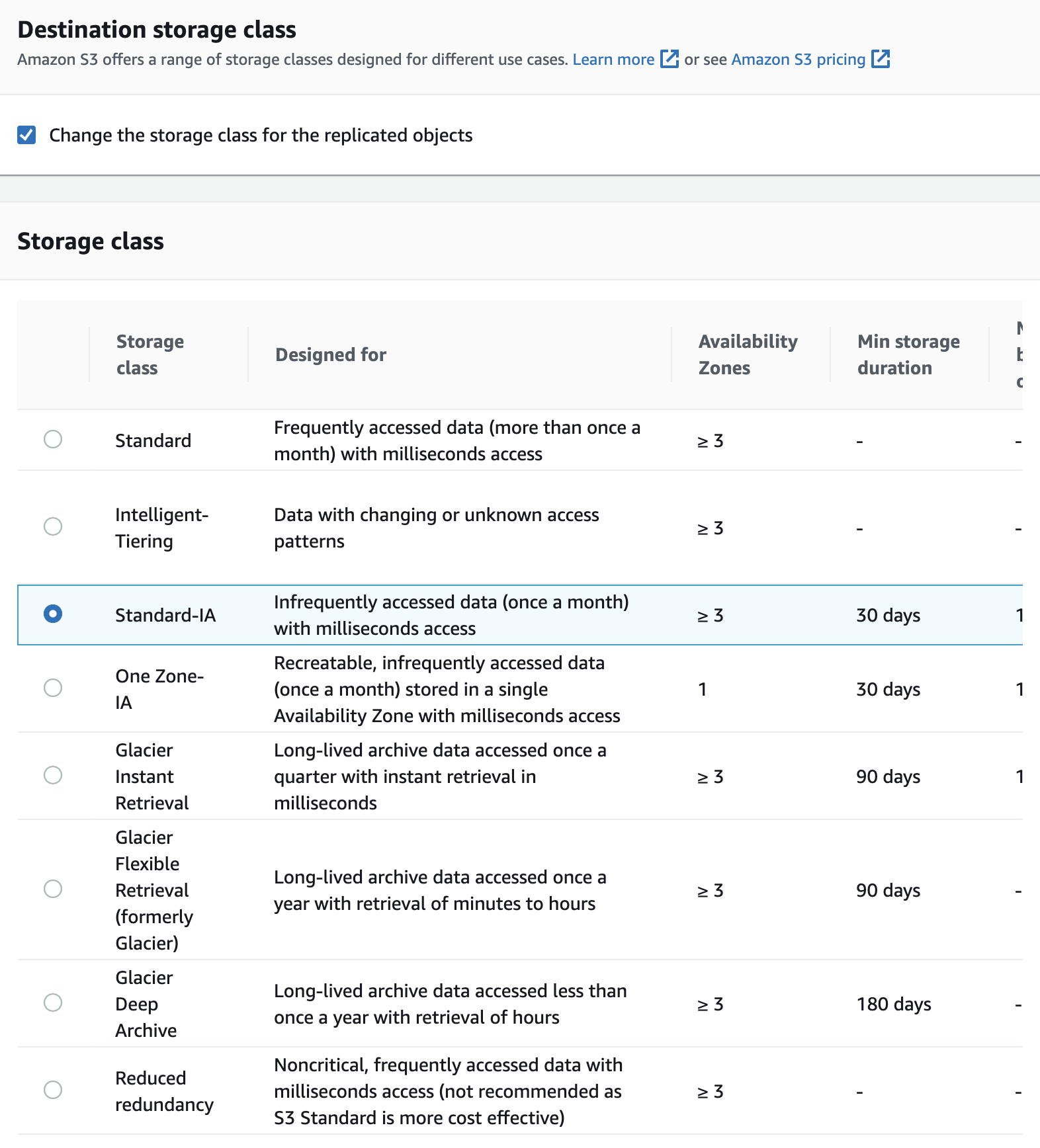
- For Destination Storage Class, you can specify a destination storage class for objects replicated in centralised S3 bucket.
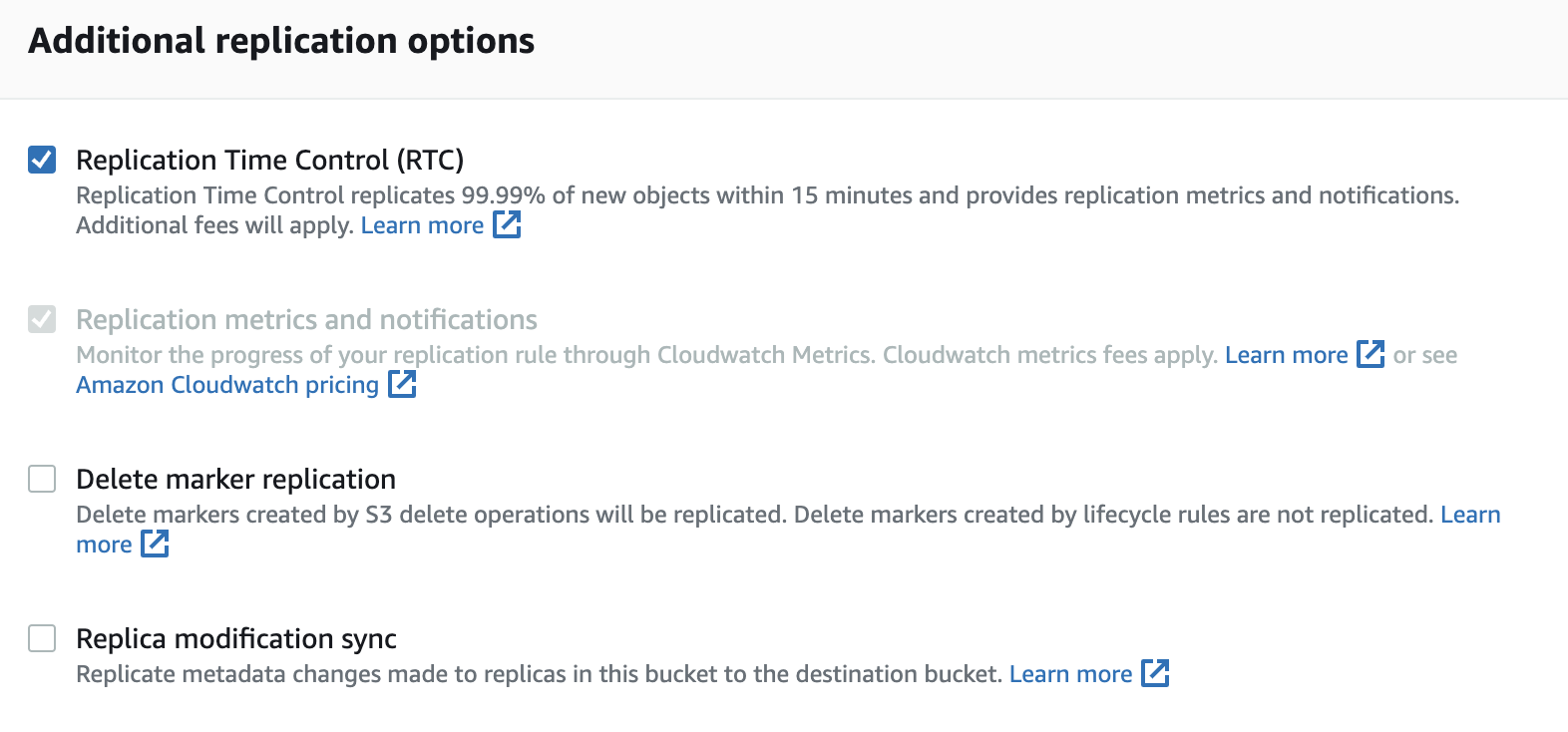
- For Additional replication options, I recommend to check box only Replication Time Control, and do not select Delete marker replication, since Delete markers created by S3 delete operations will be replicated in centralised S3 bucket
- Click Save
Test replication
To test this rule you will upload an object into the source S3 bucket in account id prefix and observe that it is replicated into the centralised S3 bucket. For this step you will need a test file
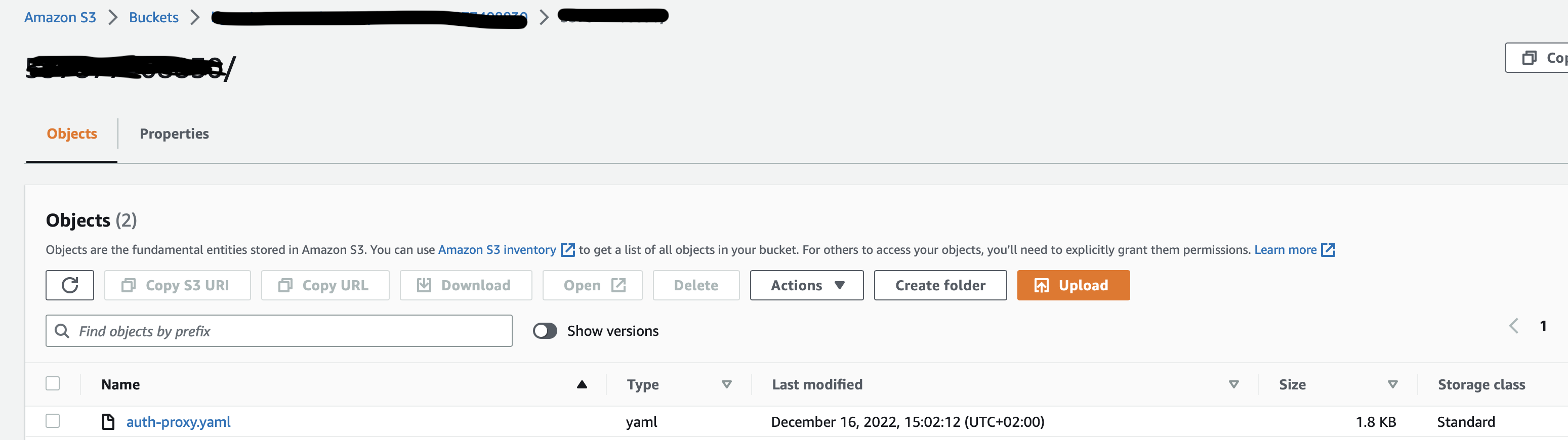
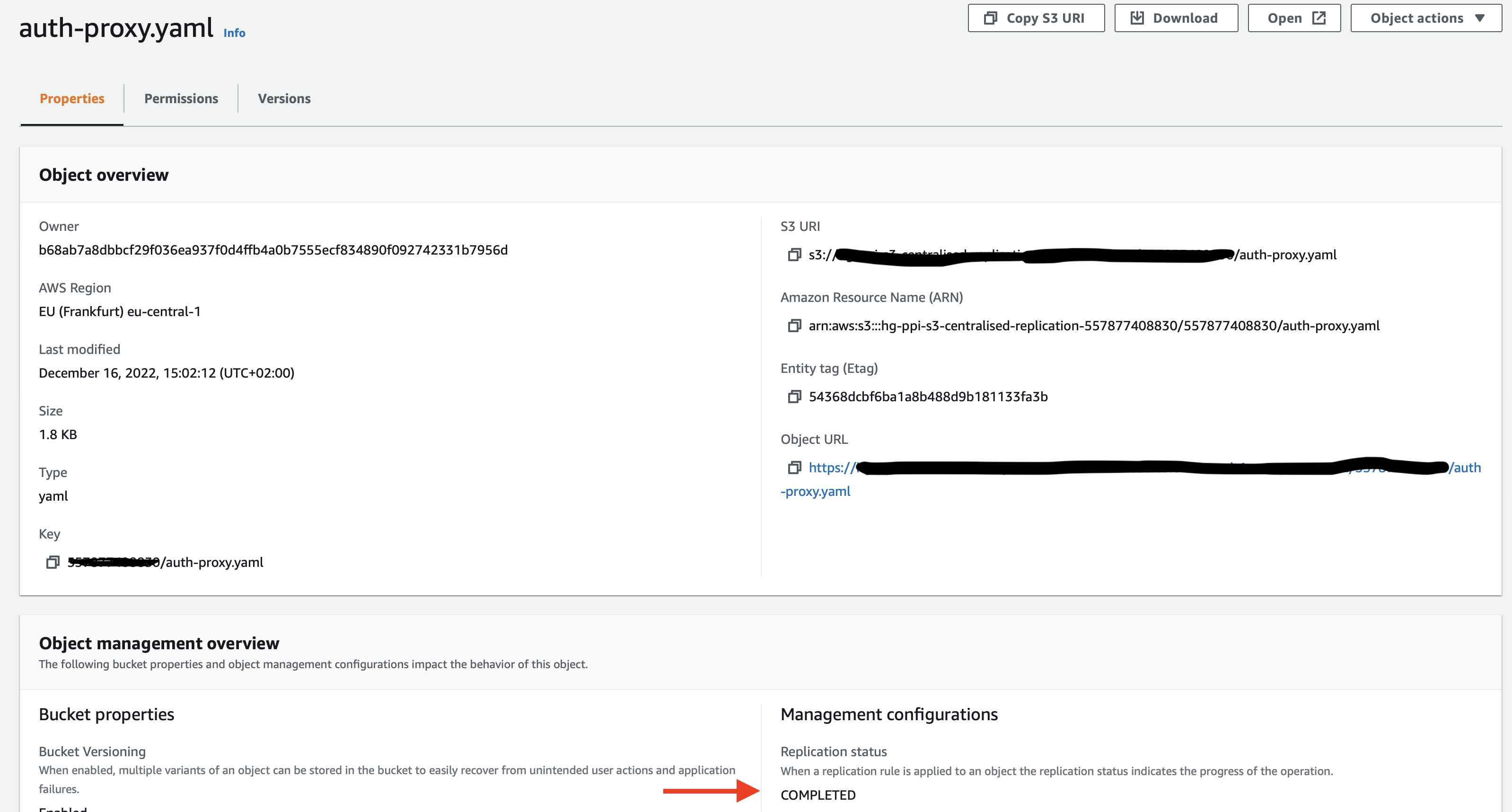
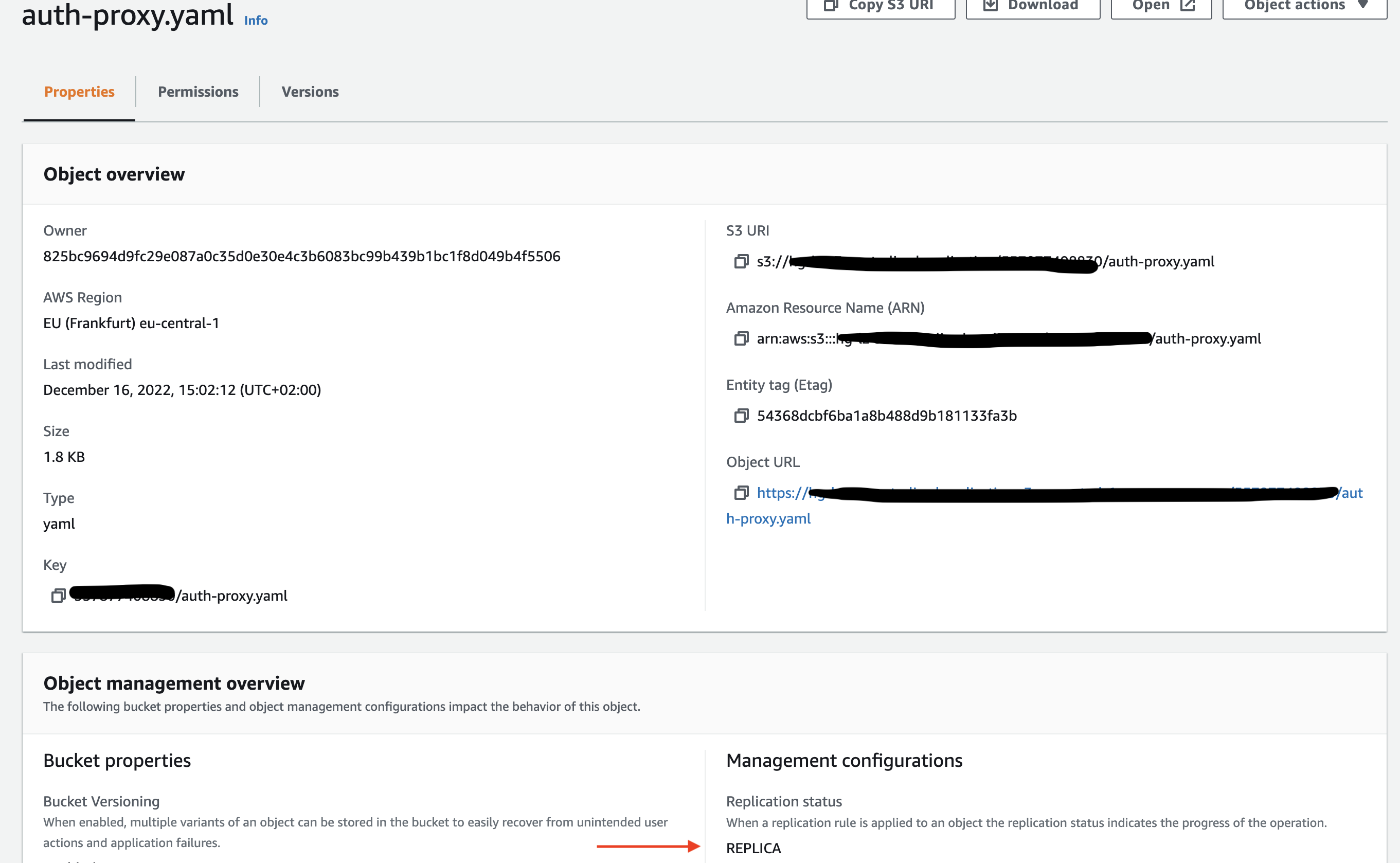
As seen, the object uploaded to source S3 bucket in the account_id prefix is replicated in centralised S3 bucket to the same prefix(account_id). This is the way you can configure a centralised S3 bucket for multiple source S3 buckets, splitting the source buckets based on the account_id prefix.