It’s the middle of 2017 and since Kubernetes has gained a lot of traction in Haufe-Lexware and other companies, it’s time to have a look at the available persistence layers for Kubernetes. In the Aurora-Team, we currently rely on a NFS instance, which in turn serves our data to our containers. This is one of the few Single-Point-Of-Failures we haven’t tackled yet and we would like to get rid of.
Our criteria are
- No vendor-lockin if possible
- Free-and-Open-Source if possible
- High-Availability
- Fast cloning / replication for Continous Integration and Deployment
- Acceptable recovery plan
Kubernetes volume organisation
Kubernetes has two different organisational layers for storage: volumes and management. The former are the persistence units kubernetes attaches to pods, while the latter is utilized by kubernetes to manage the lifecycle (e.g. creation of volumes) of the volumes and the health of the persistence layer in general. Without a management connector, external tools have to be used to manage the persistence layer, which adds complexity to the whole setup and is obviously undesired.
The contestants
For starters, we are looking at open-source software. Moving to an azure-provided storage solution would also be an option for us, since our Kubernetes-Cloud is currently running on Azure anyway. But for the sake of staying infrastructure-agnostic, we try to stay in the realm of kubernetes and team-managed nodes as much as possible.
When choosing a technology, it is important to have a look at a few management factors - especially in the highly volatile market we live in today. I generally tend to check a few factors first before diving more deeply into a possible project.
Let’s meet the contestants:
| Feature | Rook | Infinit | NFS HA via DRBD | Heketi |
|---|---|---|---|---|
| Maturity | alpha (0.4) | alpha (0.8.0) | mature (since forever) | mature (Sep 2015) |
| Project Health | moderate | unknown | healthy | moderate |
| Storage Technology | Ceph | native | native | GlusterFS |
| Complexity | complex | moderate | simple | complex |
| Entity endorsed | partly (endorsed by Quantum) | yes (Docker Inc.) | partly (Linbit Intl.) | no |
| Kubernetes Volume driver | yes (ceph) | no | yes (nfs) | yes (glusterfs) |
| Kubernetes Management connector | yes (rook) | no | no | yes (heketi) |
Rook with Ceph
![]()
![]()
![]()
Rook is the new kid on the block with it’s birth in december 2016 and is still in alpha. As Heketi does with glusterfs, Rook builds an easy-to-use abstraction layer on the complexity of an underlying storage engine - in this case Ceph. Ceph itself is endorsed by Red Hat and several other big companies, has a predictable lifecycle with Long-Term-Support and a roughly 2-year support for those. From an architectural standpoint, Ceph is highly customizable and quite complicated to set up and maintain - this is where Rook enters the stage, providing some sane defaults and automations for installing and maintaining.
Currently, the project is loosely endorsed by the employer of the main developers (Quantum Inc.), but according to one of the main developers has been invited by the Cloud Native Computing Foundation to join them. Being under the same hood as kubernetes, this would bring Rook into reach of being the primary solution for Kubernetes cloud native storage.

Still, at the time of writing, rook is missing viable features needed for production. This includes missing documentation, no automatic recovery from restarts or pod failures or the possibility to upgrade to newer versions. The roadmap shows these features planned for September 2017, but the team is behind the roadmap by quite some months.
Due to these problems, Rook is out for the moment.
Infinit
![]()
Infinit is another young project, which made some headlines when being acquired by Docker Inc. It provides some very unique features like ease of setting up, tight integration into the Docker ecosphere, high level of security through encryption during transit and during persistence, etc.
Not much has happened on their github account since they were acquired,and they are quite behind schedule on their roadmap - but integrating a company into another is a timeconsuming process. Also, while kubernetes integration has been planned for 2018, it is questionable, if that goal is still in focus - Docker provides its own cloud provider with Docker Swarm, which was supposed to be integrated in Q2/17.
Therefore, for the time being, infinit is not an option for us.
NFS HA via DRBD
![]()
For our specific usecase, we want to get rid of the SPOF represented by our current NFS VM, so one of the easiest solutions - which has been around for nearly 20 years now - is an NFS with a DRBD-replicated storage. DRBD is a GPLed storage replication software developed in 1999 and has been incorporated into the Linbit company, which now offers several additional products based on the DRBD technology - while keeping the community edition alive and supported. Due to its age, it’s a really mature software I’ve been using 15 years ago to build an NFS-HA cluster.
NFS has been around for ages as well and will not go away - however, NFS got it’s downsides. The security concept has been built in a time where security wasn’t on most peoples minds and is very limited. Development has effectively stopped since the original author - SUN Microsystems - was taken over by Oracle and the main development has been handed over to the IETF. An NFS-DRBD cluster also does not scale well beyond a certain point due to limiting the functionality to replication only.
On the plus side, the solution is very reliable by focusing on replication only and has extended it’s split brain detection and recovery methods quite significantly. The setup is also very simple in terms of moving parts and not much magic happening behind the scenes, so the number of complexity-related problems are miniscule. Due to the maturity, there’s a lot of documentation and common knowledge available. Should we choose this solution, we can easily upgrade to a paid tier with a faster support time or extend the setup with DRBD Proxy if necessary.
Due to time-contraints of the exploration, I did not go further into a possible solution, mainly because some problems like a client-handover from the primary NFS to the standby NFS-server raised some concerns on my side. Also, the missing connector for the management of volumes from kubernetes is a minus, and the next solution does seem to be the best solution to check out.
Heketi (and GlusterFS)
![]()
![]()
![]()
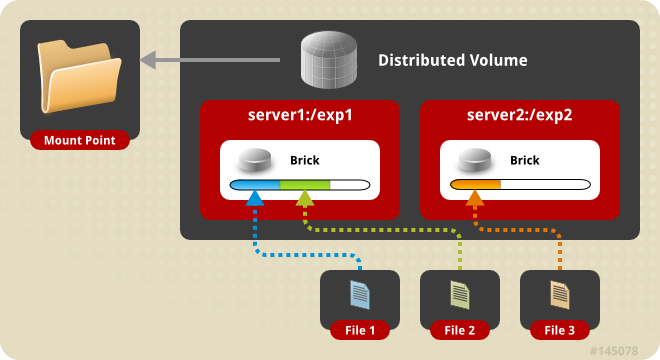
GlusterFS is a GPL-licensed, highly configurable storage system, which has been available for over a decade. Originally, it was developed by its own company Gluster Inc, which was purchased by Red Hat in 2011. GlusterFS is a - if not the - major software-defined storage solution and tackles nearly every problem of distributed persistence like replication, striping, failover, caching, live customization and authentication/authorization. It can start small and scale without problems (even petabyte clusters are known to exist). Due to the maturity of GlusterFS, a lot of documentation and support possibilities exist. However, due to the mass of functionality present, setting up and maintaining a GlusterFS cluster is quite complex and has a lot of moving parts, which requires quite some knowledge to be built in the team.
From the Kubernetes side, a volume driver to access glusterfs is natively available, but there is no native management connector option - this is where Heketi comes in. Heketi consists of a daemon with a kubernetes-compatible REST API and a commandline client to deal with GlusterFS. Since it’s a simplicity layer, it only scratches the possibilities of GlusterFS, but provides a sufficient set of opiniated use cases.
Problematic is the missing endorsement of Heketi from any entity. There is neither the possibility to get a support plan nor are Pull Requests or Issues solved in a timely manner. Even their own forked docker images of the glusterfs sidecars has been broken for 2 months straight before someone noticed (and still is at the time of writing), which is quite annoying and does not speak for their support processes or a good adoption from other companies.
Still, it’s the best shot we have beside a manual maintained NFS-DRBD-Cluster and there are no straight blockers, so… let’s head down the rabbit hole.
Setup
First of all, glusterfs is highly customizable in terms of data storage - it can save everything into directories, but can also use block storage devices. In combination with heketi, only block-storage devices are possible. For this to work, glusterfs requires direct access to the harddrives. The setup instructions of heketi suggest to install glusterfs into its own daemonset, which then requires the appropriate node directories like /dev/ to be mounted directly into the glusterfs-containers themselves. On the block-device-level, glusterfs did not re-invent the wheel for storage organization, but instead transfers that task to thinly provisioned LVMs.
When trying this approach, I ran into different problems - luckily, Sergey Nuzhdin tried this approach as well and found solutions for most of the problems. The easy ones were missing packages on the node-system, which still seem to be required for glusterfs to work even when running in containers. Dynamically provisioning persistent volumes (PVs) and -claims (PVCs) worked as advertised, but automatic deletion of the volumes of deleted containers did - and still does - not, despite setting appropriate values for the Reclaim Policy. Update (2017-08-20): The issue with automatic deletion was resolved in a bugfix release.
In general, after setup of the containers, kubernetes is informed of the IP-address of the heketi REST API in form of a storage class - using the usual kube-dns-resolver and simply setting the endpoint to heketi.svc or something similar does not work due to an unresolved issue in kubernetes. Heketi then performs the necessary glusterfs-operations like setting up an initial node topology, creating glusterfs volumes and instructing kubernetes to use these as bound PVCs.
The harder problems surfaced later after the initial setup ran for a few days: After upgrading my nodes to a new kubernetes minor version and restarting them one-by-one, the provisioning of new volumes did not work anymore and restarted containers could not claim the old devices. Heketi has two different ways of communicating with glusterfs: by utilizing kubernetes service accounts or by an sshexec. Obviously, when everything runs on kubernetes, the former approach makes more sense. After restarting the nodes, all containers (including glusterfs and heketi) had to be reprovisioned. Since I had to use IP-address for the endpoint, one of the obvious problems was a new IP-address of the heketi-container, which I updated in the config - still, the storage did not work. So I checked the gluster-containers and found them failing to start.
The gluster-containers I used were the ones provided by the heketi-project itself. Which had been failing to build for the past 2 months without anyone noticing. The main problem seems to be a change in the dockerd-behaviour when mounting /dev/ into containers and breaking binary lookup, which in turn led the gluster-containers to fail to start, which can happen - but that such a major problem has gone unnoticed for 2 months and no one seeming to care when I reported the issue is a blocker for this approach.
So, since I cannot use a big advantage of a cloud setup (dns-based service discovery) in combination with the image issue, I restarted the setup with a different approach.
Setup #2
In my second approach, I installed glusterfs 3.10 (current LTS) natively on the nodes themselves and install the heketi service directly onto the kubernetes masternode - if it’s currently impossible to use DNS-based resolving for storageclasses, I might as well use a well-known-ip instead. I was pleasantly surprised, that all data and configuration of glusterfs was taken over from the previous configuration - so at least there would not have been any dataloss. Regardless, I deleted the storage and reconfigured glusterfs and heketi to a fresh state.
Instead of heketi’s kubernetes executor, I utilized ssh with public-key-authentication for communicating with the glusterfs-nodes. This setup worked a lot better and more robust - with the obvious flaw of having created a new SPOF, which I mitigated on the application level with good old monit. Since my cluster currently runs as a single-master-setup, I got bigger problems if my master-node fails anyway.
This proved to be a better fit for our needs and was a lot more robust in light of node failures or upgrades, because the cluster will continue to work even with a failed masternode, as long as no other changes occur in the cluster.
Security
Next up I looked into the security of the setup. The heketi-endpoint is secured through the usual combination of username and password, although over an unsecured HTTP connection. The credentials of the endpoint are stored in a kubernetes secret (which for the time being are not encrypted in kubernetes at all). Securing the endpoint with an HTTPS reverse proxy and restricting access to the secret are necessary steps for a productive environment.
GlusterFS itself opens up quite a lot of ports on the nodes as well, including the rpcbind-port for NFS and several ports in the higher ranges. Worse, the default installation does not provide any form of security on the management port, allowing any node or client to join - insane defaults. As for the synchronization of the storage, glusterfs has the concept of storage blocks, which enables the system to use and mix different storage technology. For each block, a new port is opened up on the nodes and the data is synchronized via TCP - an odd choice, thinking of the overhead. For high-performance, I would have expected UDP with transport validation in a higher layer. I made necessary adjustments for the firewall to only allow the clusternodes and installed TLS-authentication for the glusterfs management as described in the kubernetes-documentation and with the help of this tutorial.
This provides at least some security, but the communication between the storage nodes and the clients has to be configured separately. Unfortunately, it does not seem to be possible to enforce a default in-transfer encryption for the complete gluster-cluster, but only on the volume level. This in turn has to be set as options for heketi when requesting a new volume, which transfers the obligation to do so onto the deployments - not a good solution, but manageable. The same is true for the in-transfer encryption of client mounts: also needs to be enabled per-volume during creation, and requires an appropriate client-certificate to be present on every container accessing the volume. In my test-setup, I used one client-certificate for all deployments, but it is also possible to use proper certificate signing with different client keys per deployment through a cluster-trusted certificate authority.
Obviously, I verified all steps with (negative) tests of the attack vectors. GlusterFS seems to be tailored towards running in private networks only and not caring much about protection, which I hope will change soon. I’d rather have an underperforming storage system than an insecure-by-default configuration opening up to data theft - especially when well-known ports often scanned by bots and with a history of being insecure are opened by default.
(Re)deployment and blue-green deployments
In the Aurora team, we are on a very good way to support continuous deployments on every aspect of our system - therefore, we also would like to get the advantages of a redeployment from a pipeline in the storage system. This is also necessary for making sure that we do not have long-running VMs or containers in our system. A regular redeployment of VMs and containers has the advantages of security making breach persistence harder, helps with memory problems and forces us to move forward with continuous deployment and integrations.
The hard part about this is the amount of downtime necessary for doing the redeployments, especially when looking at necessary access to live databases - lucky for us, glusterfs and heketi support a dynamic change of the underlying storage structure without any downtime at all. This allows for an expand-and-shrink strategy: deploy new storage nodes, add the nodes to the existing cluster, and drain and delete the original nodes. Glusterfs will automatically redistribute the data from the original bricks over to the new one.
For a better fallback strategy, we also move more and more into the direction of automatic fallback with blue-green deployments. For the storage system, this is needed for version upgrades of glusterfs, for which the aforementioned strategy of expand-and-shrink will not work or is too risky. For this, it’s a question of whether the data is held directly on the nodes itself or if the data is stored on external disks.
For node-local data, I did not find any solution without downtime - instead a new storage-cluster has to be provisioned, the application-cluster has to be put into maintenance mode (effectively disabling access to the data), the data from the old storage-cluster copied over to the new storage-cluster, and the old storage-cluster deprovisioned. Then, the application-cluster can get back up, accessing the migrated data. Copying over data from one cluster to the other can be painstakenly slow, so for our data size, I expect a downtime of about three hours for this approach. This could be reduced drastically by a hybrid approach, in which we split the data into read-write storage (like logging) and read-only storage, with the latter being the main data hog. The application-cluster could remain live, while the read-only data is copied over to the new cluster and would only have to be put into maintenance mode for the migration of the read-write storage.
If we are fine with accepting a higher dependency towards Azure, we could utilize attached azure disks to the nodes. That has the advantage of being able to secure any upgrades with snapshots, and the upgrade-process is dead simple: maintenance mode for the application cluster, stop the old storage-cluster, spawn the new one with re-attached disks of the old storage-cluster, and you’re done - restart application-cluster, expected downtime of a few minutes.
Backup
Since GlusterFS uses the host’s LVM to create and maintain volumes, a provider-agnostic backup is easily possible. All logical volumes can be iterated over and handled one-by-one. First, an lvm-snapshot is created, which GlusterFS can also do for you. This creates a live-copy of the logical volume, which will not change. This snapshot can then be backed up on a block-level via dd or on the file-level via any of your favorite tools (rsync, tar, you-name-it). Afterwards, the snapshot is deleted and the next volume can be handled.
This will also handle the heketi-db-volume, which has the current state of heketi-handled logical volumes with some configuration.
Performance
Lastly, I checked the performance of the storage cluster. I have not performed any optimization on this and checked the results with a block creation from /dev/urandom against the native speed of the nodes themselves and against a host-mounted directory. For that, I created volumes with replication levels 2 and 3 (resulting in one and two fallbacks respectively). The first performance tests were humiliating for glusterfs in terms of write-speeds of 5mb/sec, while read-speeds stayed at near-native speed.
After much debugging, this was not a problem of glusterfs itself, but of connection speed - one of my three nodes had autonegotiated down from a gigabit-connection to a 100mbit-connection. After fixing this problem, I was able to get block-write-speeds of around 45mb/sec with near-native read-speeds. This is somewhat expected, as continuous streams of write-operations have to be propagated to two other nodes and will hit the available speed of ~800mbit of my connection pretty soon.
In our specific use-case, this is not that problematic, because our main operation is read-access on the hundreds of gigabytes of product information - since that information can be loaded from the local gluster-brick, the read-speed is as fast as it gets. However, this would have to prove itself with our real application first.
Alternatives
If glusterfs will not suit us due to performance issues, we can consider loosening the restrictions we put up earlier and think outside the box. One solution would be to lock us in stronger with Microsoft Azure and rely more on their storage solutions. This would move the risk and management from a team-managed task out to a third party, without loosing any abilities, but at increased cost. Kubernetes already has two volume storage providers for Azure, so integration is pretty straight forward. The volume management part would require us to write adequate management connectors to manage these volumes out-of-band and maybe later connect our own scripts via FlexVolume Providers to get the management into kubernetes.
Another solution would be to scale out in terms of sharding - splitting the data up. We have >300 products at Haufe with different sizes (from a few mb up to dozens of gigabytes) and popularity among our clients. To optimize the sharding, we would have to take both variables into account (because a bigger size results in higher cpu- and memory-usage for the search engine), but doing so would allow a much better resource usage - although it would require more containers to not introduce a new SPOF.
Conclusion
While the state of cloud infrastructure systems has made huge leaps in the last few years, there still is no clear winner with regard to easy integration for storage. Since the main driver behind a migration to cloud still seems to be economic reasons, the technical reasons as a driving force - like provider-agnostic ease and speed of deployments without downtime - still lack behind.
This lack of easy-to-use cloud-storage solutions has also been noticed by the companies driving the change, as can be seen by Docker Inc’s acquirement of Infinit and the CNCF’s efforts with Rook. Given two years, I expect to see Infinit and Rook in a recommendable state, but for now, they are simply not ready for production. NFS’ future is unclear and there are some problems like client-handover, but despite those it is a possible solution worth investigating.
But at the moment, I would recommend using glusterfs. Start with Heketi and their opinionated approach, because it will get you results fastest. If you hit a performance-wall there, you can change your approach towards getting rid of Heketi and starting to optimize glusterfs itself.
Lars Kumbier is an IT-Consultant currently supporting Haufe-Lexware in the topics of development with angular and devops.
Header Image by Davis Turner: Reckitt-Benckiser shoot for Ryder, used under CC-BY-SA-3.0 from https://commons.wikimedia.org/wiki/File:X2_warehouse.jpg