Let’s be honest, systems age and while we try hard not to accumulate technical depth, sometimes you realize it’s time for a bigger change. In this case, we looked at a Haufe owned platform providing services like user-, licence- and subscription management for internal and external customers. Written in Java, based on various open source components, somewhat automated, fairly monolithic.
Backed by our technical strategy, we try to follow the microservices approach (a good read is Sam Newman’s book). We treat infrastructure as code and automate wherever possible. So whenever we start from scratch, it’s fairly straight forward to apply those principles.
But what if you already have your system, and it’s grown over the years? How do you start? Keeping in mind we have a business critical system on a tight budget and a busy team. Try to convince business it’s time for a technical face lift…
We decided to look at the current painpoints and start with something that shows immediate business results in a reasonably short timeframe.
Rough Idea
The team responsible for this platform has to develop, maintain and run the system. A fair amount of their time went into deploying environments for internal clients and help them get up and running. This gets even trickier when different clients use an environment for testing simultaneously. Setting up a test environment from scratch - build, deploy, test - takes 5 man days. That’s the reality we tried to improve.
We wanted to have a one click deployment of our system per internal client directly onto Azure. Everything should be built from scratch, all the time and we wanted some automated testing in there as well. To make it more fun, we decided to fix our first go live date to 8 working weeks later by hosting a public meetup in Timisoara and present what we did! The pressure (or fun, depending on your viewpoint) was on…
So time was an issue, we wanted to be fast to have something to work with. Meaning that we didn’t spend much time in evaluating every little component we used but made sure we were flexible enough to change it easily - evolutionary refinement instead of initial perfection.
How
Our guiding principles:
- Infrastructure as code - EVERYTHING. IN CONFIG FILES. CHECKED IN. No implicit knowledge in people’s heads.
- Immutable Servers - We build from scratch, the whole lot. ALWAYS. NO UPDATES, HOT FIX, NOTHING.
- Be independent of underlying infrastructure - it shouldn’t matter where we deploy to. So we picked Azure just for the fun of it.
Main components we used:
- go.cd for continous delivery
- Docker: All our components run within docker containers
- Bitbucket as repository for config files and scripts
- Team Foundation Server as code repository
- Artifactory as internal docker hub
- ELK stack for logging
- Grafana with InfluxDB for basic monitoring
The flow:
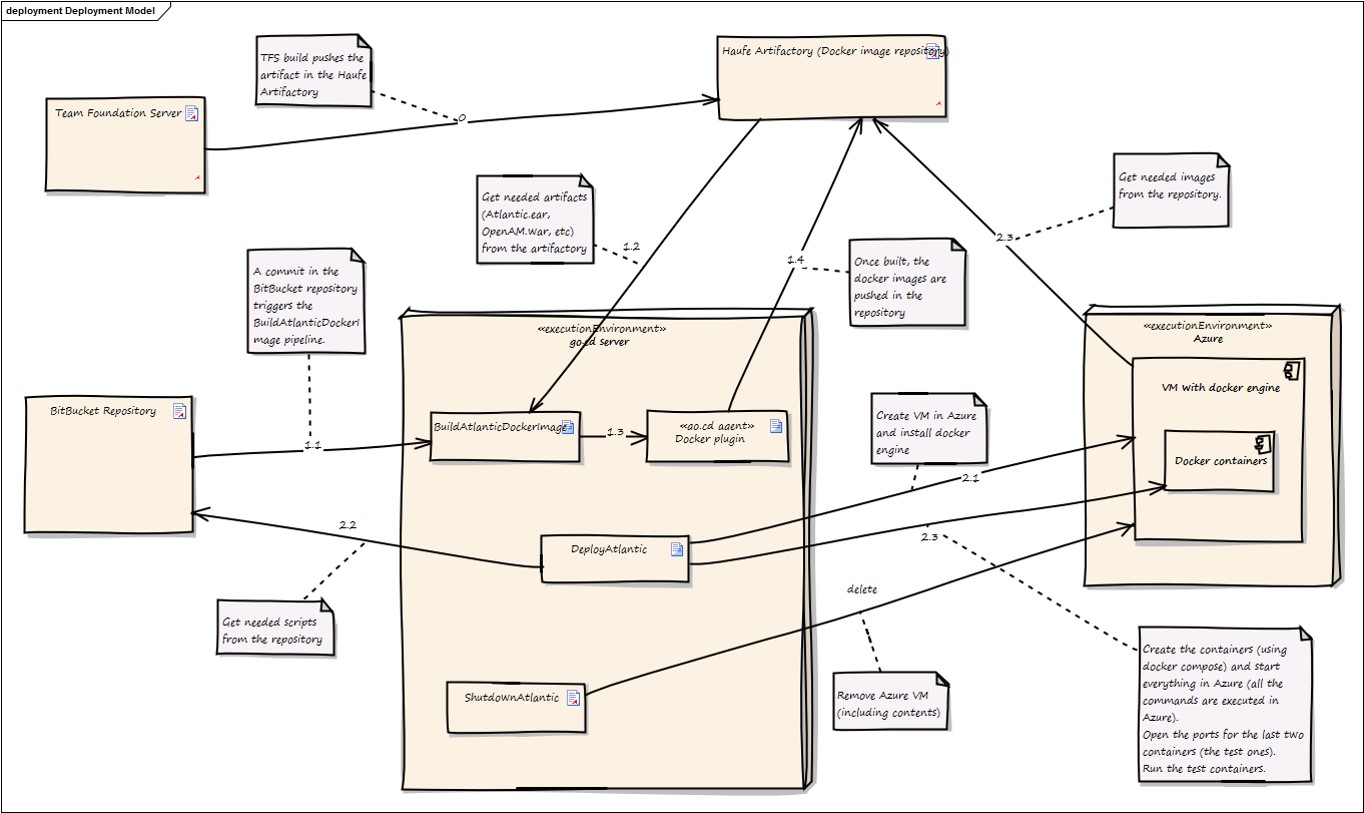
Let’s first have a quick look on how go.cd works:
Within go.cd you model your worklows using pipelines. Those pipelines contain stages which you use to run jobs which themselves contain tasks. Stages will run in order and if one fails, the pipeline will stop. Jobs will run in parallel, go.cd is taking care of that.
The trigger for a pipeline to run is called a material - so this can be a git repository where a commit will start the pipeline, but also a timer which will start the pipeline reguarly.
You can also define variables on multiple levels - we have used it on a pipeline level - where you can store things like host names and alike. There is also an option to store secure variables.
In our current setup we use three pipelines: The first on creates a docker image for every component in our infrastructure - database, message queue, application server. It builds images for the logging part - Elastic Search, Kibana and Fluentd - as well as for the monitoring and testing.
We also pull an EAR file out of our Team Foundation Server and deploy it onto the application server.
Haufe has written and open sourced a plugin to help ease the task to create docker images.
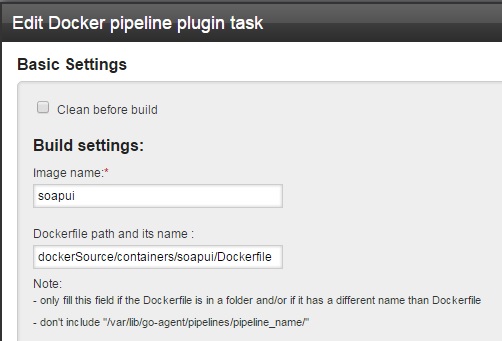
Here is how to use it:
Put in an image name and point to the dockerfile:
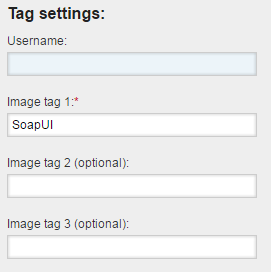
You can also tag your image:
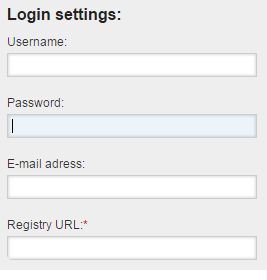
Our docker images get stored in our internal Artifactory which we use as a docker hub. You can add your repository and the credentials for that as well:
Those images are based on our docker guidelines.
The next step is to deploy our environment onto Azure. For that purpose we use a second go.cd pipeline with these stages:
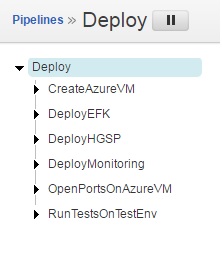
First step is to create an VM on Azure. In this case we create a custom command in go.cd and simply run a shell script:
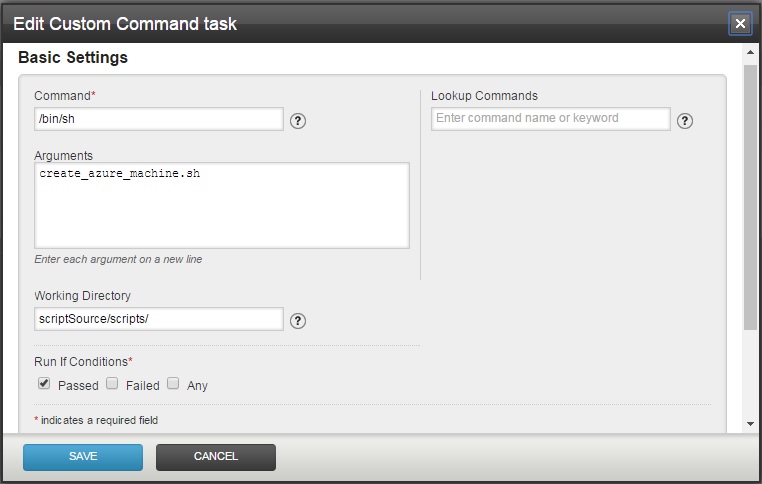
Core of the script is a docker machine command which creates an Ubuntu based VM which will serve as a docker host:
docker-machine -s ${DOCKER_LOCAL} create -d azure --azure-location="West Europe" --azure-image=${AZURE_IMAGE} --azure-size="Standard_D3" --azure-ssh-port=22 --azure-username=<your_username> --azure-password=<password> --azure-publish-settings-file azure.settings ${HOST}
Once the VM is up and running, we run docker compose commands to pull our images from Artifactory (in this case the setup of the logging infrastructure):
version: '2'
services:
elasticsearch:
image: registry.haufe.io/atlantic_fs/elasticsearch:v1.0
hostname: elasticsearch
expose:
- "9200"
- "9300"
networks:
- hgsp
fluentd:
image: registry.haufe.io/atlantic_fs/fluentd:v1.0
hostname: fluentd
ports:
- "24224:24224"
networks:
- hgsp
kibana:
env_file: .env
image: registry.haufe.io/atlantic_fs/kibana:v1.0
hostname: kibana
expose:
- "5601"
links:
- elasticsearch:elasticsearch
networks:
- hgsp
nginx:
image: registry.haufe.io/atlantic_fs/nginx:v1.0
hostname: nginx
ports:
- "4443:4443"
restart:
always
networks:
- hgsp
networks:
hgsp:
driver: bridge
As a last step we have one pipeline to simple delete everything we’ve just created.
Outcome
We kept our timeline, presented what we did and were super proud of it! We even got cake!!

Setting up a test environment now only takes 30 minutes, down from 5 days. And even that can be improved by running stuff in parallel.
We also have a solid base we can work with - and we have many ideas on how to take it further. More testing will be included soon, like more code- and security tests. We will include gates that only once the code has a certain quality or has improved in a certain way after the last test, the pipeline will proceed. We will not stop at automating the test environment, but look at our other environments as well.
All the steps necessary we have in code, which makes it repeatable and fast. There is no dependency to anything. This enables our internal clients to setup their personal environments in a fast and bulletproof way on their own.
Update: You can find slides of our talk here